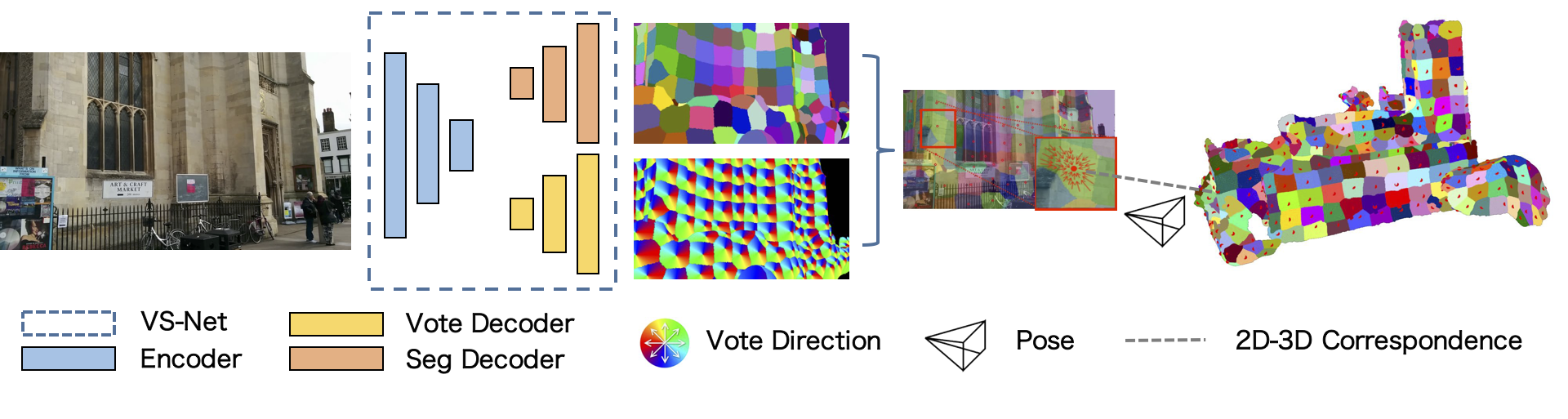
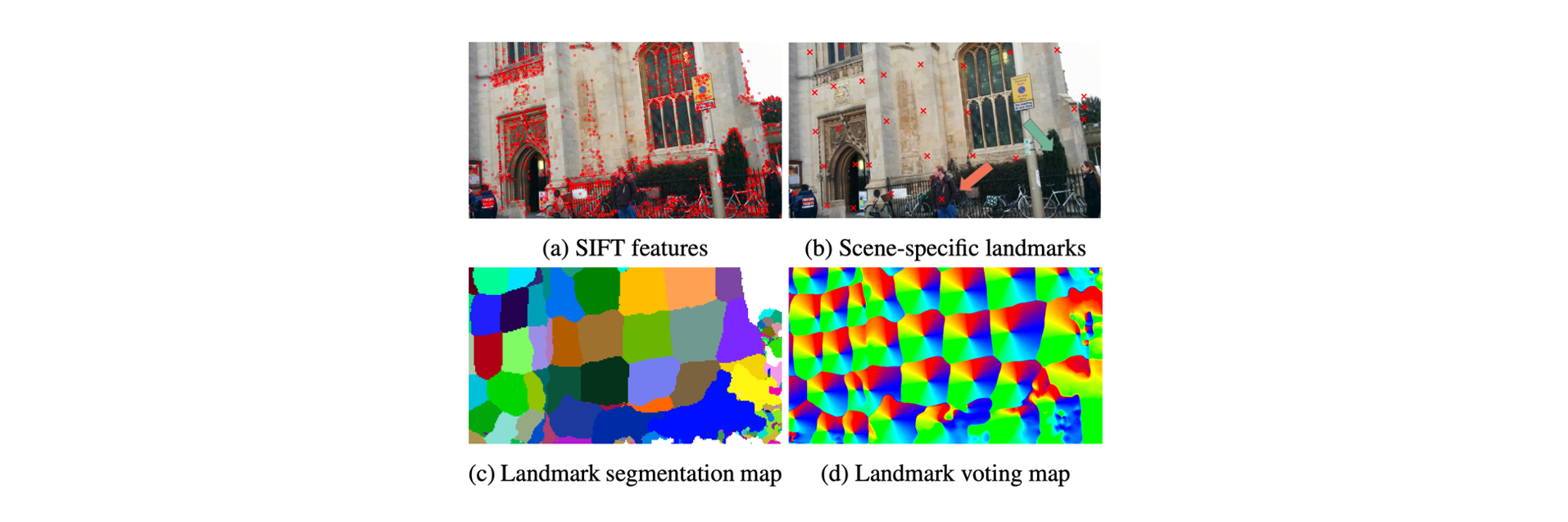
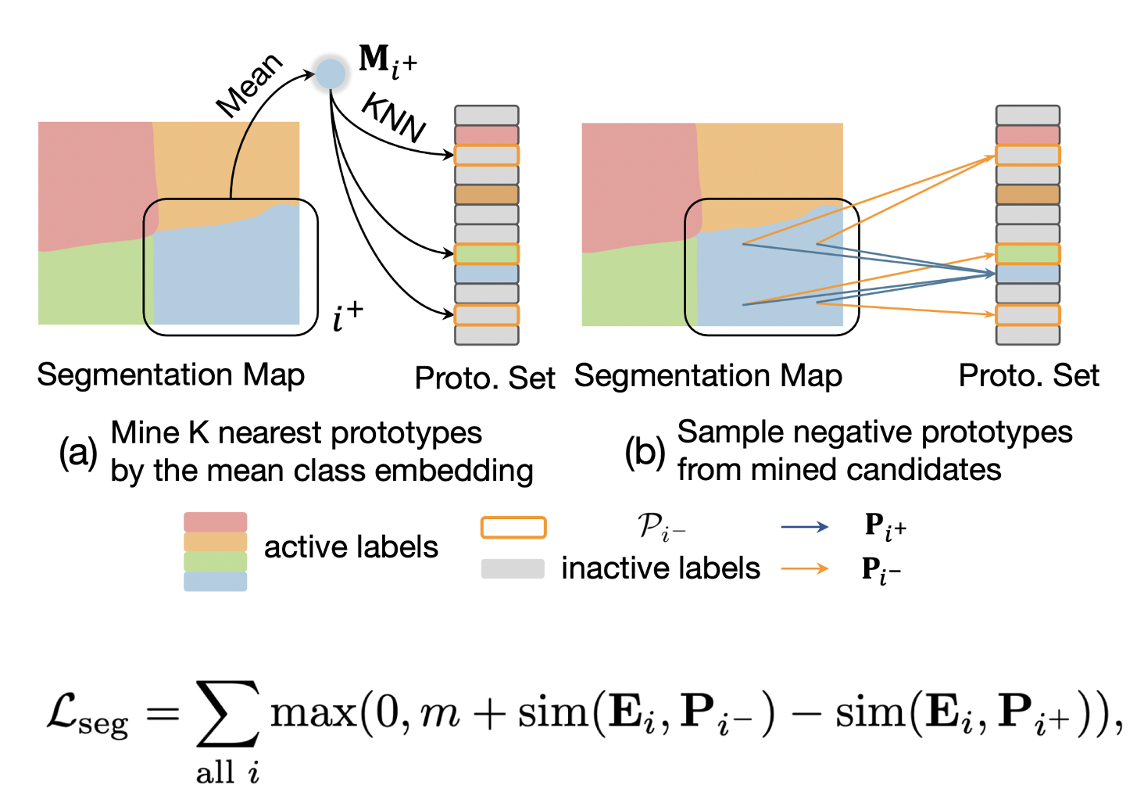
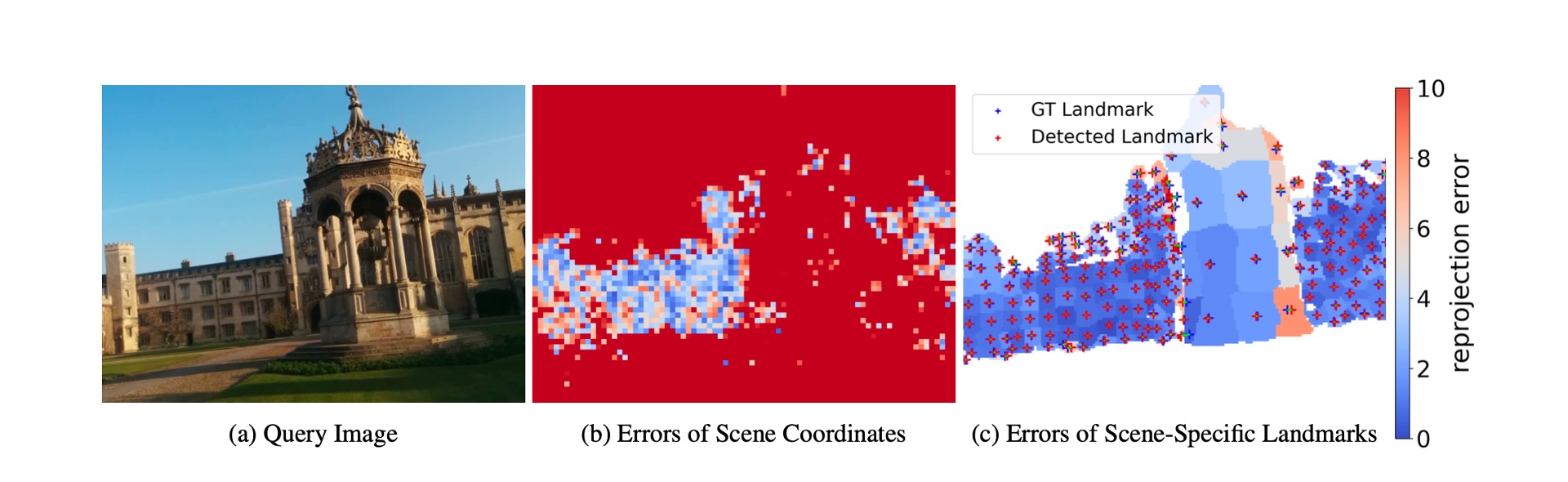
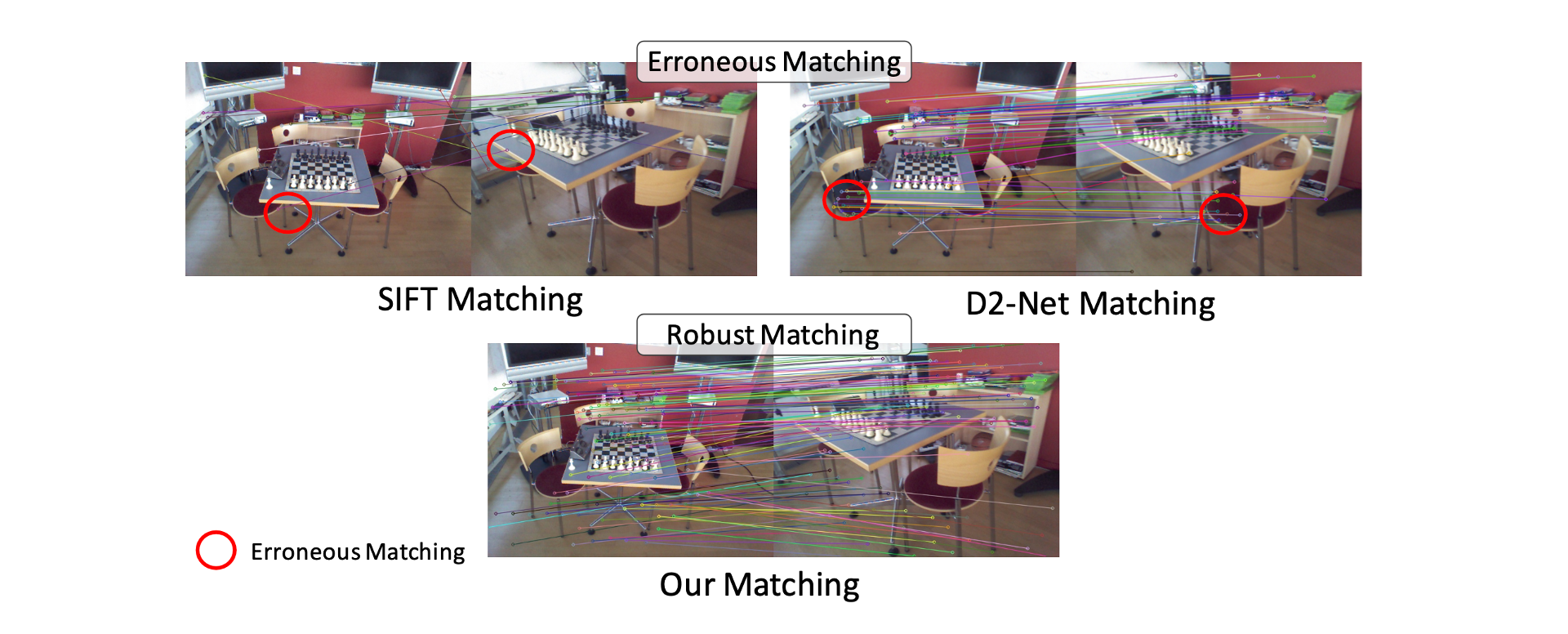
Motivation of Scene-specific Landmarks
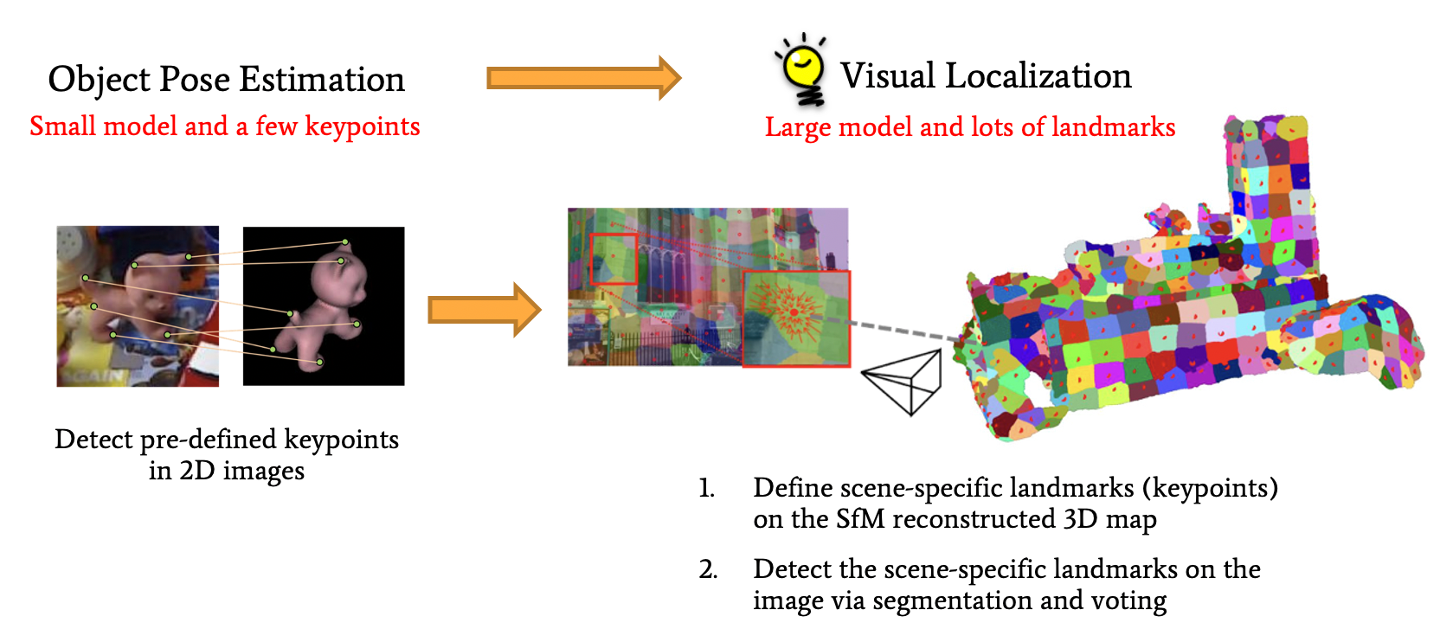
Estimating camera poses by the Pnp algorithm doesn’t require 2D-to-3D dense correspondences. Instead, sparse, uniformly distributed, and accurate correspondences can better benefit localization. Object pose estimation establishes 2D-3D correspondences by identifying predefined keypoints on the 3D model, which can produce sparse, uniformly distributed, and accurate correspondences. Inspired by them, we propose to define landmarks on the given 3D model, which are referred to as scene-specific landmarks, and train a neural network to identify such scene-specific landmarks in 2D images. Furthermore, visual localization is faced with a much larger model and should process a large number of landmarks. We propose a voting with segmentation neural network to address this problem.