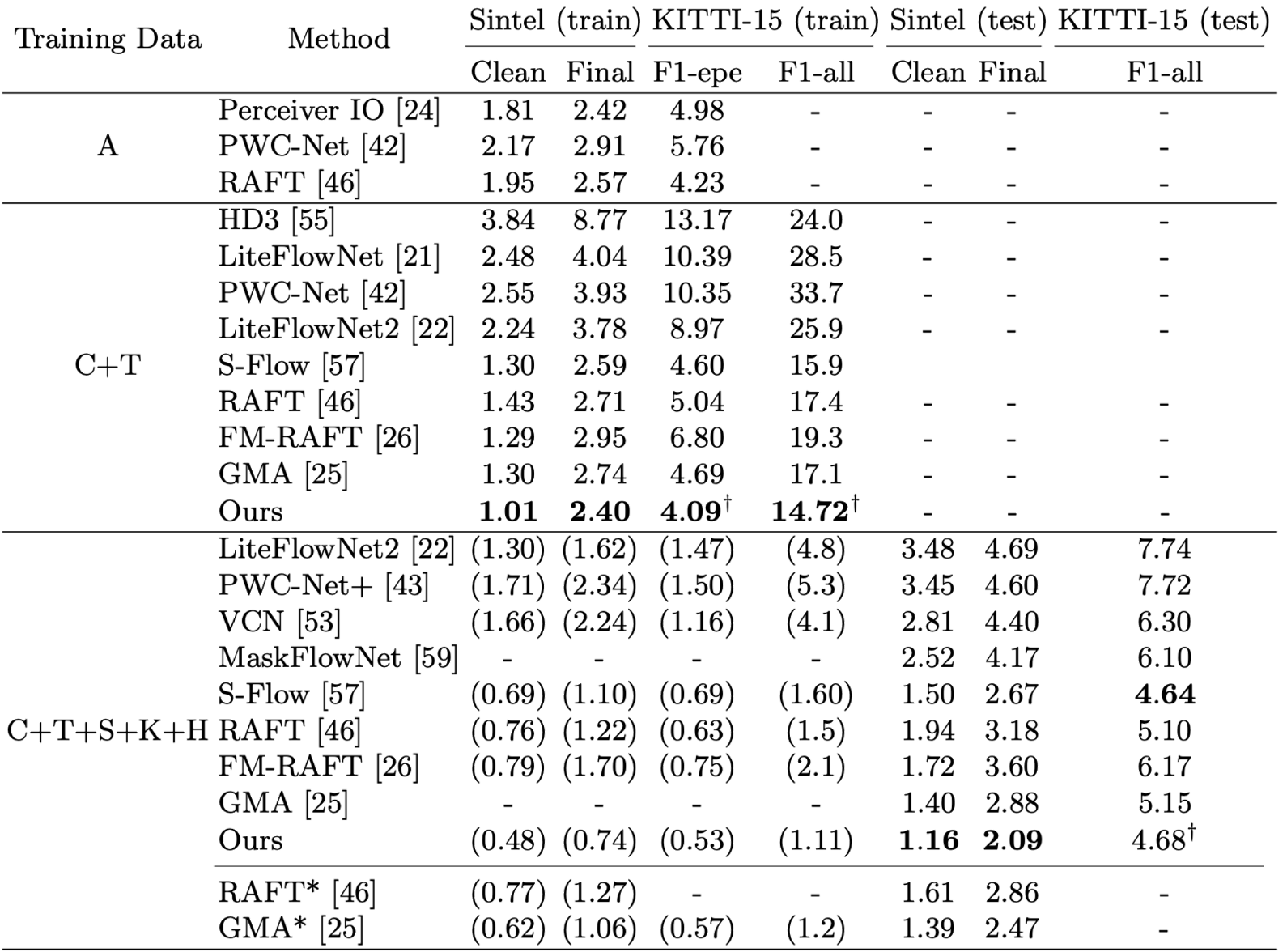
Method
Motivation
Recently, transformers have attracted much attention for their ability of modeling long-range relations, which can benefit optical flow estimation. Can we enjoy both advantages of transformers and the cost volume from the previous milestone architectures? Such a question calls for designing novel transformer architectures for optical flow estimation that can effectively aggregate information from the cost volume. In this paper, we introduce the novel optical Flow TransFormer~(FlowFormer) to address this challenging problem.
Architecture
FlowFormer adopts an encoder-decoder architecture for cost volume encoding and decoding. After building a 4D cost volume, FlowFormer consists of two main components: 1) a cost volume encoder that embeds the 4D cost volume into a latent cost space and fully encodes the cost information in such a space, and 2) a recurrent cost decoder that estimates flows from the encoded latent cost features. Compared with previous works, the main characteristic of our FlowFormer is to adapt the transformer architectures to effectively process cost volumes, which are compact yet rich representations widely explored in optical flow estimation communities, for estimating accurate optical flows.
Our contributions can be summarized as threefold: